
Elastic中文社区网站新增文章投稿功能
如果您有Elastic技术栈相关的文章想分享,可以在本站发表原创文章,或者以站外投稿(已在其他站点发表过)的方式进行发布,站外投稿就无需再重复编辑整个文章内容了,仅需要提供文章标题、摘要、稿源、链接基本信息即可。
怎么发布站外投稿文章呢?
1.入口
注册登录本站后,鼠标移动到网站右上角的“发起”按钮会弹出下拉选项,选中“文章”点击即可。如下图示例:

2.编辑&发布
文章类型选择站外投稿,填写文章来源、文章链接、文章标题、文章内容摘要等稿源信息后提交即可。如下图示例:

3.修改更新
如发布之后需要修改,可在文章详情界面点击编辑进行内容更新。如下图示例:

本站Elastic中文社区将持续整合Elastic相关最新的技术文章和资讯供大家阅览,欢迎大家在本站发布原创文章或投稿。
如有疑问或建议,欢迎在评论区留言反馈。
如果您有Elastic技术栈相关的文章想分享,可以在本站发表原创文章,或者以站外投稿(已在其他站点发表过)的方式进行发布,站外投稿就无需再重复编辑整个文章内容了,仅需要提供文章标题、摘要、稿源、链接基本信息即可。
怎么发布站外投稿文章呢?
1.入口
注册登录本站后,鼠标移动到网站右上角的“发起”按钮会弹出下拉选项,选中“文章”点击即可。如下图示例:
2.编辑&发布
文章类型选择站外投稿,填写文章来源、文章链接、文章标题、文章内容摘要等稿源信息后提交即可。如下图示例:
3.修改更新
如发布之后需要修改,可在文章详情界面点击编辑进行内容更新。如下图示例:
本站Elastic中文社区将持续整合Elastic相关最新的技术文章和资讯供大家阅览,欢迎大家在本站发布原创文章或投稿。
如有疑问或建议,欢迎在评论区留言反馈。 收起阅读 »
社区日报 第1231期 (2021-10-15)
https://elasticsearch.cn/article/14390
2、给Zblogphp插上Elasticsearch的翅膀
https://elasticsearch.cn/article/14389
3、Elasticsearch more like this 案例解读
https://qbox.io/blog/mlt-simil ... uery/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://elasticsearch.cn/article/14390
2、给Zblogphp插上Elasticsearch的翅膀
https://elasticsearch.cn/article/14389
3、Elasticsearch more like this 案例解读
https://qbox.io/blog/mlt-simil ... uery/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
使用极限网关来进行 Elasticsearch 跨集群跨版本查询及所有其它请求
使用场景
如果你的业务需要用到有多个集群,并且版本还不一样,是不是管理起来很麻烦,如果能够通过一个 API 来进行查询就方便了,聪明的你相信已经想到了 CCS,没错用 CCS 可以实现跨集群的查询,不过 Elasticsearch 提供的 CCS 对版本有一点的限制,并且需要提前做好 mTLS,也就是需要提前配置好两个集群之间的证书互信,这个免不了要重启维护,好像有点麻烦,那么问题来咯,有没有更好的方案呢?
😁 有办法,今天我就给大家介绍一个基于极限网关的方案,极限网关的网址:http://极限网关.com/。
假设现在有两个集群,一个集群是 v2.4.6,有不少业务数据,舍不得删,里面有很多好东西 :)还有一个集群是 v7.14.0,版本还算比较新,业务正在做的一个新的试点,没什么好东西,但是也得用 :(,现在老板们的的需求是希望通过在一个统一的接口就能访问这些数据,程序员懒得很,懂得都懂。
集群信息
- v2.4.6 集群的访问入口地址:192.168.3.188:9202
- v7.14.0 集群的访问入口地址:192.168.3.188:9206
这两个集群都是 http 协议的。
实现步骤
今天用到的是极限网关的 switch 过滤器:https://极限网关.com/docs/references/filters/switch/
网关下载下来就两个文件,一个主程序,一个配置文件,记得下载对应操作系统的包。
定义两个集群资源
elasticsearch:
- name: v2
enabled: true
endpoint: http://192.168.3.188:9202
- name: v7
enabled: true
endpoint: http://192.168.3.188:9206上面定义了两个集群,分别命名为 v2 和 v7,待会会用到这些资源。
定义一个服务入口
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 1000
network:
binding: 0.0.0.0:8000
tls:
enabled: true这里定义了一个名为 my_es_entry 的资源入口,并引用了一个名为 my_router 的请求转发路由,同时绑定了网卡的 0.0.0.0:8000 也就是所有本地网卡监听 IP 的 8000 端口,访问任意 IP 的 8000 端口就能访问到这个网关了。
另外老板也说了,Elasticsearch 用 HTTP 协议简直就是裸奔,通过这里开启 tls,可以让网关对外提供的是 HTTPS 协议,这样用户连接的 Elasticsearch 服务就自带 buffer 了,后端的 es 集群和网关直接可以做好网络流量隔离,集群不用动,简直完美。
为什么定义 TLS 不用指定证书,好用的软件不需要这么麻烦,就这样,不解释。
最后,通过设置 max_concurrency 为 1000,限制下并发数,避免野猴子把我们的后端的 Elasticsearch 给压挂了。
定义一个请求路由
router:
- name: my_router
default_flow: cross-cluster-search这里的名称 my_router 就是表示上面的服务入口的router 参数指定的值。
另外设置一个 default_flow 来将所有的请求都转发给一个名为 cross-cluster-search 的请求处理流程,还没定义,别急,马上。
定义请求处理流程
来啦,来啦,先定义两个 flow,如下,分别名为 v2-flow 和 v7-flow,每节配置的 filter 定义了一系列过滤器,用来对请求进行处理,这里就用了一个 elasticsearch 过滤器,也就是转发请求给指定的 Elasticsearch 后端服务器,了否?
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7然后,在定义额外一个名为 cross-cluster-search 的 flow,如下:
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow这个 flow 就是通过请求的路径的前缀来进行路由的过滤器,如果是 v2:开头的请求,则转发给 v2-flow 继续处理,如果是 v7: 开头的请求,则转发给 v7-flow 来处理,使用的用法和 CCS 是一样的。so easy!
对了,那是不是每个请求都需要加前缀啊,费事啊,没事,在这个 cross-cluster-search 的 filter 最后再加上一个 elasticsearch filter,前面前缀匹配不上的都会走它,假设默认都走 v7,最后完整的 flow 配置如下:
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow
- elasticsearch:
elasticsearch: v7 然后就没有然后了,因为就配置这些就行了。
启动网关
假设配置文件的路径为 sample-configs/cross-cluster-search.yml,运行如下命令:
➜ gateway git:(master) ✗ ./bin/gateway -config sample-configs/cross-cluster-search.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2021-10-15 16:25:56, 3d0a1cd
[10-16 11:00:52] [INF] [app.go:228] initializing gateway.
[10-16 11:00:52] [INF] [instance.go:24] workspace: data/gateway/nodes/0
[10-16 11:00:52] [INF] [api.go:260] api listen at: http://0.0.0.0:2900
[10-16 11:00:52] [INF] [reverseproxy.go:257] elasticsearch [v7] hosts: [] => [192.168.3.188:9206]
[10-16 11:00:52] [INF] [entry.go:225] auto generating cert files
[10-16 11:00:52] [INF] [actions.go:223] elasticsearch [v2] is available
[10-16 11:00:52] [INF] [actions.go:223] elasticsearch [v7] is available
[10-16 11:00:53] [INF] [entry.go:296] entry [my_es_entry] listen at: https://0.0.0.0:8000
[10-16 11:00:53] [INF] [app.go:309] gateway is running now.可以看到网关输出了启动成功的日志,网关服务监听在 https://0.0.0.0:8000 。
试试访问网关
直接访问网关的 8000 端口,因为是网关自签的证书,加上 -k 来跳过证书的校验,如下:
➜ loadgen git:(master) ✗ curl -k https://localhost:8000
{
"name" : "LENOVO",
"cluster_name" : "es-v7140",
"cluster_uuid" : "npWjpIZmS8iP_p3GK01-xg",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}正如前面配置所配置的一样,默认请求访问的就是 v7 集群。
访问 v2 集群
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:/
{
"name" : "Solomon O'Sullivan",
"cluster_name" : "es-v246",
"cluster_uuid" : "cqlpjByvQVWDAv6VvRwPAw",
"version" : {
"number" : "2.4.6",
"build_hash" : "5376dca9f70f3abef96a77f4bb22720ace8240fd",
"build_timestamp" : "2017-07-18T12:17:44Z",
"build_snapshot" : false,
"lucene_version" : "5.5.4"
},
"tagline" : "You Know, for Search"
}查看集群信息:
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:_cluster/health\?pretty
{
"cluster_name" : "es-v246",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}插入一条文档:
➜ loadgen git:(master) ✗ curl-json -k https://localhost:8000/v2:medcl/doc/1 -d '{"name":"hello world"}'
{"_index":"medcl","_type":"doc","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}% 执行一个查询
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:medcl/_search\?q\=name:hello
{"took":78,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":0.19178301,"hits":[{"_index":"medcl","_type":"doc","_id":"1","_score":0.19178301,"_source":{"name":"hello world"}}]}}% 可以看到,所有的请求,不管是集群的操作,还是索引的增删改查都可以,而 Elasticsearch 自带的 CCS 是只读的,只能进行查询。
访问 v7 集群
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v7:/
{
"name" : "LENOVO",
"cluster_name" : "es-v7140",
"cluster_uuid" : "npWjpIZmS8iP_p3GK01-xg",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Kibana 里面访问
完全没问题,有图有真相:

其他操作也类似,就不重复了。
完整的配置
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
tls:
enabled: true
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow
- elasticsearch:
elasticsearch: v7
router:
- name: my_router
default_flow: cross-cluster-search
elasticsearch:
- name: v2
enabled: true
endpoint: http://192.168.3.188:9202
- name: v7
enabled: true
endpoint: http://192.168.3.188:9206小结
好了,今天给大家分享的如何使用极限网关来进行 Elasticsearch 跨集群跨版本的操作就到这里了,希望大家周末玩的开心。😁
使用场景
如果你的业务需要用到有多个集群,并且版本还不一样,是不是管理起来很麻烦,如果能够通过一个 API 来进行查询就方便了,聪明的你相信已经想到了 CCS,没错用 CCS 可以实现跨集群的查询,不过 Elasticsearch 提供的 CCS 对版本有一点的限制,并且需要提前做好 mTLS,也就是需要提前配置好两个集群之间的证书互信,这个免不了要重启维护,好像有点麻烦,那么问题来咯,有没有更好的方案呢?
😁 有办法,今天我就给大家介绍一个基于极限网关的方案,极限网关的网址:http://极限网关.com/。
假设现在有两个集群,一个集群是 v2.4.6,有不少业务数据,舍不得删,里面有很多好东西 :)还有一个集群是 v7.14.0,版本还算比较新,业务正在做的一个新的试点,没什么好东西,但是也得用 :(,现在老板们的的需求是希望通过在一个统一的接口就能访问这些数据,程序员懒得很,懂得都懂。
集群信息
- v2.4.6 集群的访问入口地址:192.168.3.188:9202
- v7.14.0 集群的访问入口地址:192.168.3.188:9206
这两个集群都是 http 协议的。
实现步骤
今天用到的是极限网关的 switch 过滤器:https://极限网关.com/docs/references/filters/switch/
网关下载下来就两个文件,一个主程序,一个配置文件,记得下载对应操作系统的包。
定义两个集群资源
elasticsearch:
- name: v2
enabled: true
endpoint: http://192.168.3.188:9202
- name: v7
enabled: true
endpoint: http://192.168.3.188:9206上面定义了两个集群,分别命名为 v2 和 v7,待会会用到这些资源。
定义一个服务入口
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 1000
network:
binding: 0.0.0.0:8000
tls:
enabled: true这里定义了一个名为 my_es_entry 的资源入口,并引用了一个名为 my_router 的请求转发路由,同时绑定了网卡的 0.0.0.0:8000 也就是所有本地网卡监听 IP 的 8000 端口,访问任意 IP 的 8000 端口就能访问到这个网关了。
另外老板也说了,Elasticsearch 用 HTTP 协议简直就是裸奔,通过这里开启 tls,可以让网关对外提供的是 HTTPS 协议,这样用户连接的 Elasticsearch 服务就自带 buffer 了,后端的 es 集群和网关直接可以做好网络流量隔离,集群不用动,简直完美。
为什么定义 TLS 不用指定证书,好用的软件不需要这么麻烦,就这样,不解释。
最后,通过设置 max_concurrency 为 1000,限制下并发数,避免野猴子把我们的后端的 Elasticsearch 给压挂了。
定义一个请求路由
router:
- name: my_router
default_flow: cross-cluster-search这里的名称 my_router 就是表示上面的服务入口的router 参数指定的值。
另外设置一个 default_flow 来将所有的请求都转发给一个名为 cross-cluster-search 的请求处理流程,还没定义,别急,马上。
定义请求处理流程
来啦,来啦,先定义两个 flow,如下,分别名为 v2-flow 和 v7-flow,每节配置的 filter 定义了一系列过滤器,用来对请求进行处理,这里就用了一个 elasticsearch 过滤器,也就是转发请求给指定的 Elasticsearch 后端服务器,了否?
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7然后,在定义额外一个名为 cross-cluster-search 的 flow,如下:
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow这个 flow 就是通过请求的路径的前缀来进行路由的过滤器,如果是 v2:开头的请求,则转发给 v2-flow 继续处理,如果是 v7: 开头的请求,则转发给 v7-flow 来处理,使用的用法和 CCS 是一样的。so easy!
对了,那是不是每个请求都需要加前缀啊,费事啊,没事,在这个 cross-cluster-search 的 filter 最后再加上一个 elasticsearch filter,前面前缀匹配不上的都会走它,假设默认都走 v7,最后完整的 flow 配置如下:
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow
- elasticsearch:
elasticsearch: v7 然后就没有然后了,因为就配置这些就行了。
启动网关
假设配置文件的路径为 sample-configs/cross-cluster-search.yml,运行如下命令:
➜ gateway git:(master) ✗ ./bin/gateway -config sample-configs/cross-cluster-search.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2021-10-15 16:25:56, 3d0a1cd
[10-16 11:00:52] [INF] [app.go:228] initializing gateway.
[10-16 11:00:52] [INF] [instance.go:24] workspace: data/gateway/nodes/0
[10-16 11:00:52] [INF] [api.go:260] api listen at: http://0.0.0.0:2900
[10-16 11:00:52] [INF] [reverseproxy.go:257] elasticsearch [v7] hosts: [] => [192.168.3.188:9206]
[10-16 11:00:52] [INF] [entry.go:225] auto generating cert files
[10-16 11:00:52] [INF] [actions.go:223] elasticsearch [v2] is available
[10-16 11:00:52] [INF] [actions.go:223] elasticsearch [v7] is available
[10-16 11:00:53] [INF] [entry.go:296] entry [my_es_entry] listen at: https://0.0.0.0:8000
[10-16 11:00:53] [INF] [app.go:309] gateway is running now.可以看到网关输出了启动成功的日志,网关服务监听在 https://0.0.0.0:8000 。
试试访问网关
直接访问网关的 8000 端口,因为是网关自签的证书,加上 -k 来跳过证书的校验,如下:
➜ loadgen git:(master) ✗ curl -k https://localhost:8000
{
"name" : "LENOVO",
"cluster_name" : "es-v7140",
"cluster_uuid" : "npWjpIZmS8iP_p3GK01-xg",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}正如前面配置所配置的一样,默认请求访问的就是 v7 集群。
访问 v2 集群
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:/
{
"name" : "Solomon O'Sullivan",
"cluster_name" : "es-v246",
"cluster_uuid" : "cqlpjByvQVWDAv6VvRwPAw",
"version" : {
"number" : "2.4.6",
"build_hash" : "5376dca9f70f3abef96a77f4bb22720ace8240fd",
"build_timestamp" : "2017-07-18T12:17:44Z",
"build_snapshot" : false,
"lucene_version" : "5.5.4"
},
"tagline" : "You Know, for Search"
}查看集群信息:
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:_cluster/health\?pretty
{
"cluster_name" : "es-v246",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}插入一条文档:
➜ loadgen git:(master) ✗ curl-json -k https://localhost:8000/v2:medcl/doc/1 -d '{"name":"hello world"}'
{"_index":"medcl","_type":"doc","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}% 执行一个查询
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:medcl/_search\?q\=name:hello
{"took":78,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":0.19178301,"hits":[{"_index":"medcl","_type":"doc","_id":"1","_score":0.19178301,"_source":{"name":"hello world"}}]}}% 可以看到,所有的请求,不管是集群的操作,还是索引的增删改查都可以,而 Elasticsearch 自带的 CCS 是只读的,只能进行查询。
访问 v7 集群
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v7:/
{
"name" : "LENOVO",
"cluster_name" : "es-v7140",
"cluster_uuid" : "npWjpIZmS8iP_p3GK01-xg",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Kibana 里面访问
完全没问题,有图有真相:
其他操作也类似,就不重复了。
完整的配置
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
tls:
enabled: true
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow
- elasticsearch:
elasticsearch: v7
router:
- name: my_router
default_flow: cross-cluster-search
elasticsearch:
- name: v2
enabled: true
endpoint: http://192.168.3.188:9202
- name: v7
enabled: true
endpoint: http://192.168.3.188:9206小结
好了,今天给大家分享的如何使用极限网关来进行 Elasticsearch 跨集群跨版本的操作就到这里了,希望大家周末玩的开心。😁
收起阅读 »给Zblogphp插上Elasticsearch的翅膀
找遍了zblog的应用中心,未发现有使用Elasticsearch搜索引擎的插件。国庆闲来无事,根据zblogphp的机制,开发了一个基于Elasticsearch的插件。
本插件使用简单,需要有一个Elasticsearch7.x的环境(基于7.x版本开发),Elasticsearch 安装[IK](https://github.com/medcl/elasticsearch-analysis-ik)、[pinyin](https://github.com/medcl/elast ... pinyin),[中文简繁體转换](https://github.com/medcl/elast ... onvert) 插件。安装好该插件后,只需要配置好账号密码,点击创建索引模板即可。发布和编辑文章时,会自动根据索引模板,创建post索引,同步文章数据。搜索时,直接接管原有的搜索逻辑,无需调整程序和模板。
后台配置截图:

配置好连接,端口,账号和密码,点击“测试连接”,弹出连接成功,展示版本号,即可点击保存配置,如果这4项错误,连接不上Elasticsearch,获取不到ES的版本号,将无法保存配置。

看到这个提示,便可以点击“保持配置”。这里有一项“切换搜索 Elasticsearch”,开启,前端搜索即切换到了Elastisearch搜索引擎。

在配置好了基本设置以后,点击索引模板,可以预览到索引模板,点击“创建索引模板”,即可在Elasticsearch服务器创建好索引模板,成功后,会在说明栏展示绿色的“已创建”,如果未创建,展示红色的“未创建”。发布和编辑文章时,会根据该索引模板,自动创建好索引,同步文章。
以下是搜索效果截图:

找遍了zblog的应用中心,未发现有使用Elasticsearch搜索引擎的插件。国庆闲来无事,根据zblogphp的机制,开发了一个基于Elasticsearch的插件。
本插件使用简单,需要有一个Elasticsearch7.x的环境(基于7.x版本开发),Elasticsearch 安装[IK](https://github.com/medcl/elasticsearch-analysis-ik)、[pinyin](https://github.com/medcl/elast ... pinyin),[中文简繁體转换](https://github.com/medcl/elast ... onvert) 插件。安装好该插件后,只需要配置好账号密码,点击创建索引模板即可。发布和编辑文章时,会自动根据索引模板,创建post索引,同步文章数据。搜索时,直接接管原有的搜索逻辑,无需调整程序和模板。
后台配置截图:
配置好连接,端口,账号和密码,点击“测试连接”,弹出连接成功,展示版本号,即可点击保存配置,如果这4项错误,连接不上Elasticsearch,获取不到ES的版本号,将无法保存配置。
看到这个提示,便可以点击“保持配置”。这里有一项“切换搜索 Elasticsearch”,开启,前端搜索即切换到了Elastisearch搜索引擎。
在配置好了基本设置以后,点击索引模板,可以预览到索引模板,点击“创建索引模板”,即可在Elasticsearch服务器创建好索引模板,成功后,会在说明栏展示绿色的“已创建”,如果未创建,展示红色的“未创建”。发布和编辑文章时,会根据该索引模板,自动创建好索引,同步文章。
以下是搜索效果截图:
收起阅读 »
@wt 社区日报 第1230期 (2021-10-11)
https://mp.weixin.qq.com/s/6Lt7YTotrlkyVuFJKR2l_g
2. Filebeat 实现剖析
https://mp.weixin.qq.com/s/RJed7ZBzvHdH0hFkWZekBw
3.从分布式一致性算法到区块链共识机制
https://mp.weixin.qq.com/s/LOUDWn7evcePCPGWar8vEA
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://mp.weixin.qq.com/s/6Lt7YTotrlkyVuFJKR2l_g
2. Filebeat 实现剖析
https://mp.weixin.qq.com/s/RJed7ZBzvHdH0hFkWZekBw
3.从分布式一致性算法到区块链共识机制
https://mp.weixin.qq.com/s/LOUDWn7evcePCPGWar8vEA
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
通过python脚本迁移ES的template模板
通过python脚本迁移ES的template模板
通过python脚本迁移ES的template模板,从192.168.0.1 迁移到 192.168.0.2
import base64
import json
import requests
def putTemplate(templateName, templateDslJson):
print("{0} 索引模板正在迁移中".format(templateName))
res = requests.put("http://192.168.0.2:9200/_template/{0}".format(templateName), json=templateDslJson)
print(res.status_code)
print(res.content)
def getTemplateDslJson():
username = "elastic"
password = "123456"
user_info_str = username + ":" + password
user_info = base64.b64encode(user_info_str.encode()) # 这个得到是个字节类型的数据
headers = {
"Authorization": "Basic {0}".format(user_info.decode()) # 这个就是需要验证的信息
}
url = "http://192.168.0.1:9200/_template/*_template"
res = requests.get(url, headers=headers)
print(res.status_code)
return json.loads(res.content)
if __name__ == '__main__':
jsonTemplate = getTemplateDslJson()
if isinstance(jsonTemplate, dict):
for templateName in jsonTemplate:
templateDslJson = jsonTemplate[templateName]
putTemplate(templateName, templateDslJson)
通过python脚本迁移ES的template模板
通过python脚本迁移ES的template模板,从192.168.0.1 迁移到 192.168.0.2
import base64
import json
import requests
def putTemplate(templateName, templateDslJson):
print("{0} 索引模板正在迁移中".format(templateName))
res = requests.put("http://192.168.0.2:9200/_template/{0}".format(templateName), json=templateDslJson)
print(res.status_code)
print(res.content)
def getTemplateDslJson():
username = "elastic"
password = "123456"
user_info_str = username + ":" + password
user_info = base64.b64encode(user_info_str.encode()) # 这个得到是个字节类型的数据
headers = {
"Authorization": "Basic {0}".format(user_info.decode()) # 这个就是需要验证的信息
}
url = "http://192.168.0.1:9200/_template/*_template"
res = requests.get(url, headers=headers)
print(res.status_code)
return json.loads(res.content)
if __name__ == '__main__':
jsonTemplate = getTemplateDslJson()
if isinstance(jsonTemplate, dict):
for templateName in jsonTemplate:
templateDslJson = jsonTemplate[templateName]
putTemplate(templateName, templateDslJson)
Elastic:使用 docker 来安装 Elastic Stack 8.0-alpha2
请注意:
这是一个 alpha 发布版。 仅将其用于测试,不要指望最终能够升级到 8.0.0 版本最终版本。
期待将会有一些这样或者那样的 bug。 这就是我们再次运行 Elastic Pioneer Program 的原因,以便我们可以解决尽可能多的问题。
这是保持简单的最小示例,例如跳过 TLS 证书(尽管这可能会改变)。 请不要将其用作生产环境。
在今天的文章中,我将详细地介绍如何安装 Elastic Stack 8.0-alpha2 版本。
原文链接:https://blog.csdn.net/UbuntuTo ... 24770
请注意:
这是一个 alpha 发布版。 仅将其用于测试,不要指望最终能够升级到 8.0.0 版本最终版本。
期待将会有一些这样或者那样的 bug。 这就是我们再次运行 Elastic Pioneer Program 的原因,以便我们可以解决尽可能多的问题。
这是保持简单的最小示例,例如跳过 TLS 证书(尽管这可能会改变)。 请不要将其用作生产环境。
在今天的文章中,我将详细地介绍如何安装 Elastic Stack 8.0-alpha2 版本。
原文链接:https://blog.csdn.net/UbuntuTo ... 24770 收起阅读 »
社区日报 第1299期 (2021-09-25)
1.使用Winlogbeats收集windows logs
https://kyletopasna.medium.com/collecting-windows-logs-with-elastics-winlogbeats-4961bc3004b6
2.ES地理位置和性状查询示例
https://medium.com/geekculture/elastic-search-geo-point-and-geo-shape-queries-explained-df69ec157527
3.解决配置K8S中遇到的no matches for kind "Elasticsearch"
https://stackoverflow.com/questions/69313889/how-can-i-make-k8s-find-elasticsearch-kind-type
1.使用Winlogbeats收集windows logs
https://kyletopasna.medium.com/collecting-windows-logs-with-elastics-winlogbeats-4961bc3004b6
2.ES地理位置和性状查询示例
https://medium.com/geekculture/elastic-search-geo-point-and-geo-shape-queries-explained-df69ec157527
3.解决配置K8S中遇到的no matches for kind "Elasticsearch"
https://stackoverflow.com/questions/69313889/how-can-i-make-k8s-find-elasticsearch-kind-type
收起阅读 »Elastic 7.15 版:数秒之内打造强大的个性化搜索体验
在 Elastic 7.15 版中,正式推出了 Elastic App Search 网络爬虫,并与 Google Cloud 实现了更加紧密的集成 — 这让我们的客户和社区能够更快地打造强大的新网络搜索体验,更快速、更安全地采集数据,并更轻松地利用搜索的力量让数据发挥作用。
此外,借助 Elastic 可观测性中新增的 APM 关联功能,DevOps 团队可以通过自动显现与高延迟或错误事务关联的属性,加快根本原因分析的速度并缩短平均解决时间 (MTTR)。
而且,俗话说得好,一不做二不休,如果打算要观测……何不(同时)保护呢?
为此,在 Elastic 7.15 版中,Elastic 安全对 Limitless XDR(扩展检测与响应)进行了增强,既能够为几乎所有的操作系统提供恶意行为保护功能,又能够为云原生 Linux 环境提供一键式主机隔离功能。
https://elasticstack.blog.csdn ... 82102
在 Elastic 7.15 版中,正式推出了 Elastic App Search 网络爬虫,并与 Google Cloud 实现了更加紧密的集成 — 这让我们的客户和社区能够更快地打造强大的新网络搜索体验,更快速、更安全地采集数据,并更轻松地利用搜索的力量让数据发挥作用。
此外,借助 Elastic 可观测性中新增的 APM 关联功能,DevOps 团队可以通过自动显现与高延迟或错误事务关联的属性,加快根本原因分析的速度并缩短平均解决时间 (MTTR)。
而且,俗话说得好,一不做二不休,如果打算要观测……何不(同时)保护呢?
为此,在 Elastic 7.15 版中,Elastic 安全对 Limitless XDR(扩展检测与响应)进行了增强,既能够为几乎所有的操作系统提供恶意行为保护功能,又能够为云原生 Linux 环境提供一键式主机隔离功能。
https://elasticstack.blog.csdn ... 82102 收起阅读 »
社区日报 第1298期 (2021-09-25)
https://www.elastic.co/cn/blog ... -15-0
2、elasticsearch-py 8.0 roadmap
https://github.com/elastic/ela ... /1696
3、Kafka +Elasticsearch 实战
https://doordash.engineering/2 ... xing/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://www.elastic.co/cn/blog ... -15-0
2、elasticsearch-py 8.0 roadmap
https://github.com/elastic/ela ... /1696
3、Kafka +Elasticsearch 实战
https://doordash.engineering/2 ... xing/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
收起阅读 »
社区日报 第1297期 (2021-09-18)
https://www.cnblogs.com/yjmyzz/p/14586637.html
2.新特性: 根据地理空间数据定制ES地图
https://www.elastic.co/blog/wh ... tions
3.ES极限网关合辑
http://gateway.infini.sh/
编辑:wt
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://www.cnblogs.com/yjmyzz/p/14586637.html
2.新特性: 根据地理空间数据定制ES地图
https://www.elastic.co/blog/wh ... tions
3.ES极限网关合辑
http://gateway.infini.sh/
编辑:wt
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第1296期 (2021-09-16)
https://elasticstack.blog.csdn ... 60616
2.Elasticsearch未分配分片异常处理
https://www.jianshu.com/p/db38d8bab7ee
3.ElasticSearch 双数据中心建设在新网银行的实践
https://mp.weixin.qq.com/s/Q8o8FbU7w1I3VoexB06cBQ
编辑:金桥
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://elasticstack.blog.csdn ... 60616
2.Elasticsearch未分配分片异常处理
https://www.jianshu.com/p/db38d8bab7ee
3.ElasticSearch 双数据中心建设在新网银行的实践
https://mp.weixin.qq.com/s/Q8o8FbU7w1I3VoexB06cBQ
编辑:金桥
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
Polygon开发者入门Workshop——从️0搭建自己的LendingPool
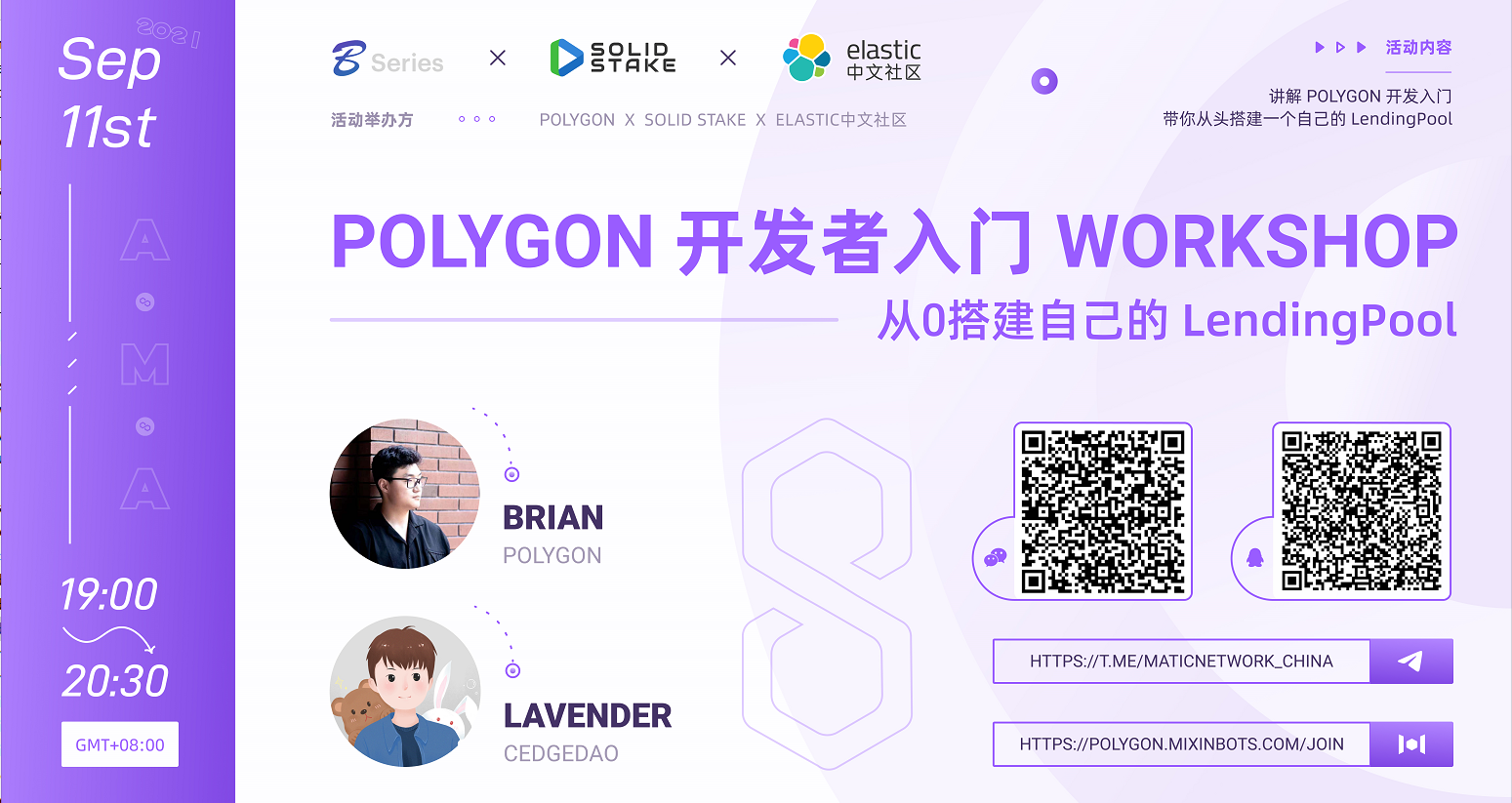
Polygon Weekly AMA
活动主题:
《Polygon开发者入门Workshop——从️搭建自己的LendingPool》
活动时间:
9月11号晚上7点
活动举办方:
Polygon x SolidStake x Elastic中文社区
活动地点:
扫码进AMA微信群! 会议号是:193 658 608
Polygon Weekly AMA
活动主题:
《Polygon开发者入门Workshop——从️搭建自己的LendingPool》
活动时间:
9月11号晚上7点
活动举办方:
Polygon x SolidStake x Elastic中文社区
活动地点:
扫码进AMA微信群! 会议号是:193 658 608
收起阅读 »社区日报 第1294期 (2021-09-04)
1.怎么为每个索引选择合适的分片?
https://opster.com/elasticsearch-glossary/elasticsearch-choose-number-of-shards/?kinsta-cache-cleared=true
2.在kibana使用德国高速公路数据示例
https://spinscale.de/posts/2021-09-01-using-german-highway-api-data-with-kibana-maps.html
3.在es查询中查找实体名的方法
https://stackoverflow.com/questions/55989250/how-to-find-entity-in-search-query-in-elasticsearch
1.怎么为每个索引选择合适的分片?
https://opster.com/elasticsearch-glossary/elasticsearch-choose-number-of-shards/?kinsta-cache-cleared=true
2.在kibana使用德国高速公路数据示例
https://spinscale.de/posts/2021-09-01-using-german-highway-api-data-with-kibana-maps.html
3.在es查询中查找实体名的方法
https://stackoverflow.com/questions/55989250/how-to-find-entity-in-search-query-in-elasticsearch
收起阅读 »社区日报 第1293期 (2021-09-03)
https://www.elastic.co/guide/e ... .html
2、Elasticsearch 垃圾回收算法解读
https://blog.bigdataboutique.c ... toq2j
3、零停机reindex实践
https://tuleism.github.io/blog ... ndex/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://www.elastic.co/guide/e ... .html
2、Elasticsearch 垃圾回收算法解读
https://blog.bigdataboutique.c ... toq2j
3、零停机reindex实践
https://tuleism.github.io/blog ... ndex/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »


